
Kafka란
Kafka는 분산 스트리밍 플랫폼으로, 주로 실시간 데이터 피드의 빅 데이터 처리를 목적으로 사용된다.
Kafka는 메시지 큐와 유사하지만, 대용량 데이터 스트림을 저장하고 실시간으로 분석하거나 처리하는 데 중점을 둔다.
💡 처리하는 메시지량: kafka >>> RabbitMQ
Kafka의 역할
- 실시간 데이터 처리: 대용량 데이터를 실시간으로 처리하고 분석한다.
- 데이터 통합: 다양한 소스에서 데이터를 수집하고 이를 통합하여 분석한다.
- 내결함성: 데이터 손실 없이 안정적으로 데이터를 저장하고 전송한다.
Kafka 장단점
- -장점- -
신뢰성
- 데이터 복제: 데이터를 여러 브로커에 복제하여 저장하므로, 단일 브로커 장애 시에도 데이터 손실을 방지할 수 있다.
- 확인 메커니즘: 데이터가 소비자에게 성공적으로 전달되었는지 확인하는 기능을 제공한다.
유연성 및 확장성
- 다양한 소비자 패턴: 여러 소비자가 동시에 데이터를 구독할 수 있다.
- 프로토콜 지원: 기본적으로 Kafka의 프로토콜을 사용하지만, 다양한 클라이언트를 통해 다른 언어에서도 사용할 수 있다.
- 분산 시스템: 클러스터링을 통해 여러 노드에서 데이터를 분산 처리할 수 있다.
- 수평 확장: 브로커와 파티션을 추가하여 쉽게 확장할 수 있다.
성능
- 높은 처리량: 대용량 데이터를 실시간으로 빠르게 처리할 수 있다.
- 저지연: 데이터 전송의 지연을 최소화하여 실시간 처리가 가능하다.
관리 및 모니터링 용이
- 다양한 관리 도구를 통해 클러스터를 모니터링하고 관리할 수 있으며, 플러그인을 통해 기능을 확장할 수 있다.
- -단점- -
- 초기 설정이 다소 복잡하며, 클러스터링 및 분산 환경에서는 더 많은 설정이 필요하다.
- 메모리와 CPU 자원을 많이 소비해 운영 비용이 크다.
❗ 알맞은 상황에 사용하지 않으면 모든 것이 단점이 될 수 있다. 특히, 카프카는 오버엔지니어링을 조심해야 할 것 같다.
Kafka의 기본 구성 요소
메시지(Message)
Kafka를 통해 전달되는 데이터 단위
메시지는 키(key), 값(value), 타임스탬프(timestamp), 그리고 몇 가지 메타데이터로 구성된다.
프로듀서(Producer)
메시지를 생성하고 Kafka에 보내는 역할을 한다.
예를 들어, 웹 애플리케이션이 로그 데이터를 Kafka에 보내는 경우 프로듀서가 된다.
프로듀서는 특정 토픽(topic)에 메시지를 보낸다.
토픽(Topic)
메시지를 저장하는 장소로 메시지는 토픽에 저장되었다가 소비자에게 전달된다.
토픽은 여러 파티션(partition)으로 나누어질 수 있으며, 파티션은 메시지를 순서대로 저장한다.
파티션을 통해 병렬 처리가 가능하다.
Ex) “user-activity”라는 토픽에 사용자의 활동 로그를 저장할 수 있다.
파티션(Partition)
파티션은 토픽을 물리적으로 나눈 단위로, 각 파티션은 독립적으로 메시지를 저장하고 관리한다.
각 파티션은 메시지를 순서대로 저장하며, 파티션 내의 메시지는 고유한 오프셋(offset)으로 식별된다.
파티션을 통해 데이터를 병렬로 처리할 수 있으며, 클러스터 내의 여러 브로커에 분산시켜 저장할 수 있다.
키(Key)
키는 메시지를 특정 파티션에 할당하는 데 사용되는 값이다.
동일한 키를 가진 메시지는 항상 동일한 파티션에 저장된다. (키 → 파티션 구분)
Ex) 특정 사용자 ID를 키로 사용하여 해당 사용자의 모든 이벤트가 동일한 파티션에 저장되도록 할 수 있다.
컨슈머(Consumer)
토픽에서 메시지를 가져와 처리한다.
컨슈머는 특정 컨슈머 그룹(consumer group)에 속하며, 같은 그룹에 속한 컨슈머들은 토픽의 파티션을 분산 처리한다.
기본적으로 컨슈머는 스티키 파티셔닝(Sticky Partitioning)을 사용한다.
이는 특정 컨슈머가 특정 파티션에 붙어서 계속해서 데이터를 처리하는 방식으로,
이는 데이터 지역성을 높여 캐시 히트율을 증가시키고 전반적인 처리 성능을 향상시킨다.
브로커(Broker)
Kafka 클러스터의 각 서버를 의미하며, 메시지를 저장하고 컨슈머에게 전송하는 역할을 한다.
하나의 Kafka 클러스터는 여러 브로커로 구성될 수 있으며, 각 브로커는 하나 이상의 토픽 파티션을 관리한다.
주키퍼(Zookeeper)
Kafka 클러스터를 관리하고 조정한다.
주키퍼는 브로커의 메타데이터를 저장하고, 브로커 간의 상호작용을 조정한다.
KRaft 모드와 주키퍼 모드가 있다.
Kafka와 RabbitMQ의 차이점
설계 철학
- RabbitMQ: 전통적인 메시지 브로커, 메시지의 안정적 전달과 큐잉에 중점
- Kafka: 분산 스트리밍 플랫폼, 대규모 실시간 데이터 스트림의 저장과 분석에 중점
메시지 모델
- RabbitMQ: 큐(queue)를 중심으로 메시지를 전달한다. 메시지는 큐에 저장되고, 큐에서 하나 이상의 컨슈머에게 전달된다.
- Kafka: 토픽(topic)을 중심으로 메시지를 저장한다. 메시지는 토픽의 파티션에 저장되고, 컨슈머는 파티션에서 메시지를 읽는다.
메시지 지속성
- RabbitMQ: 메시지를 메모리나 디스크에 저장할 수 있으며, 일반적으로 단기 저장을 목표로 한다.
- Kafka: 메시지를 디스크에 저장하며, 장기 저장을 목표로 한다. 데이터 로그는 설정된 기간 동안 보존된다.
사용 사례
- RabbitMQ: 작업 큐, 요청/응답 패턴, 비동기 작업 처리 등 전통적인 메시지 큐 사용 사례
- Kafka: 실시간 데이터 스트리밍, 로그 수집 및 분석, 이벤트 소싱 등 대규모 데이터 스트림 처리에 적합
❗ Queue 안에서는 FIFO 성질에 의해 처리 순서가 보장되지만 여러 개의 컨슈머가 존재할 때, 각각의 컨슈머 단에서 처리 순서는 보장할 수 없다.
Kafka 연동 테스트
docker-compose.yml
services:
zookeeper:
image: confluentinc/cp-zookeeper:latest
container_name: zookeeper
ports:
- "2181:2181"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_SERVER_ID: 1
kafka:
image: confluentinc/cp-kafka:latest
container_name: kafka
ports:
- "9092:9092"
- "29092:29092"
environment:
KAFKA_ADVERTISED_LISTENERS: INTERNAL://kafka:19092,EXTERNAL://${DOCKER_HOST_IP:-127.0.0.1}:9092,DOCKER://host.docker.internal:29092
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: INTERNAL:PLAINTEXT,EXTERNAL:PLAINTEXT,DOCKER:PLAINTEXT
KAFKA_INTER_BROKER_LISTENER_NAME: INTERNAL
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
KAFKA_BROKER_ID: 1
depends_on:
- zookeeper
kafka-ui:
image: provectuslabs/kafka-ui:latest
container_name: kafka-ui
depends_on:
- kafka
ports:
- 8081:8081
environment:
KAFKA_CLUSTERS_0_NAME: local
KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS: kafka:29092
KAFKA_CLUSTERS_0_ZOOKEEPER: zookeeper:2181
docker compose up -d 하면 image를 pull 받고 container 실행까지 해준다.
그런데 다음과 같은 에러가 발생했다.
Error response from daemon: NotFound: content digest sha256:d8cc95d7a6df6556197e118b7bb1264742ae91c1ba21dbdb4b1a22b0f0909f57: not found
이미지 pull 과정에서 문제가 생긴 듯하다.
docker compose down --rmi all 명령어로 이미지를 제거한 다음 다시 수행했다.
잘 돌아가고 있는 것을 확인할 수 있다.

localhost:8080에 접속해서 kafka-ui를 살펴보자.
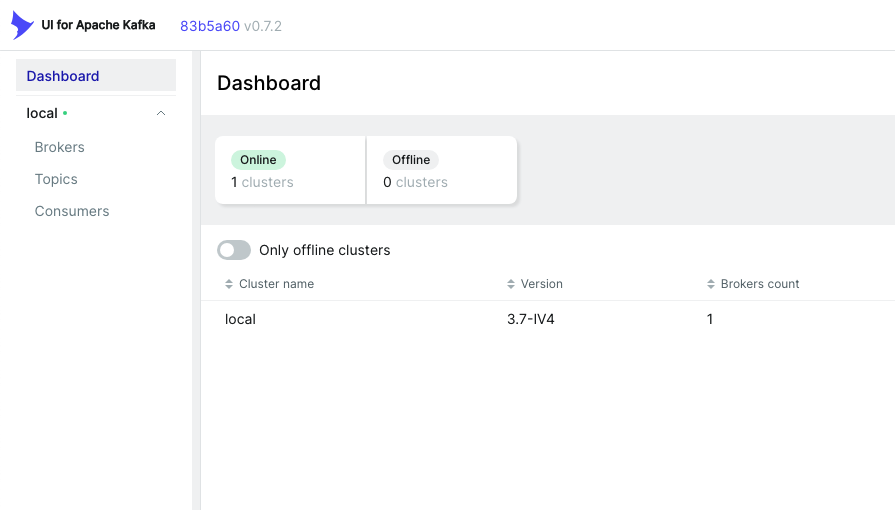
스프링 부트 연동
depencency > Spring for Apache Kafka 추가 > producer 프로젝트 생성

Consumer를 만들때도 동일하다.
producer > application.yml
spring:
application:
name: producer
kafka:
bootstrap-servers: localhost:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
server:
port: 8090
producer > KafkaConfig
@Configuration
public class ProducerAppKafkaConfig {
@Bean
public ProducerFactory<String, String> producerFactory() {
Map<String, Object> configProps = new HashMap<>();
configProps.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProps.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
configProps.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
return new DefaultKafkaProducerFactory<>(configProps);
}
@Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<>(producerFactory());
}
}
producer > ProducerController
@RestController
@RequiredArgsConstructor
public class ProducerController {
private final ProducerService producerService;
@GetMapping("/send")
public String sendMessage(@RequestParam("topic") String topic,
@RequestParam("key") String key,
@RequestParam("message") String message) {
producerService.sendMessage(topic, key, message);
return "Message sent to Kafka topic";
}
}
RequestParam으로 topic, key, message를 받는다.
producer > ProducerService
@Service
@RequiredArgsConstructor
public class ProducerService {
private final KafkaTemplate<String, String> kafkaTemplate;
public void sendMessage(String topic , String key, String message) {
for (int i = 0; i < 10; i++) {
kafkaTemplate.send(topic, key, message + " " + i);
}
}
}
Bean 등록한 KafkaTemplate을 활용하여 간단한 message를 보낸다.
comsumer > application.yml
spring:
application:
name: consumer
kafka:
bootstrap-servers: localhost:9092
consumer:
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
server:
port: 8091
consumer > KafkaConfig
@EnableKafka // Kafka 리스너 활성화
@Configuration
public class ConsumerAppKafkaConfig {
// Kafka 컨슈머 팩토리 생성 빈 정의
// ConsumerFactory는 Kafka 컨슈머 인스턴스를 생성하는 데 사용된다.
// 각 컨슈머는 이 팩토리를 통해 생성된 설정을 기반으로 작동한다.
@Bean
public ConsumerFactory<String, String> consumerFactory() {
Map<String, Object> configProps = new HashMap<>();
// Kafka 브로커의 주소를 설정
configProps.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
// 메시지 키의 역직렬화 클래스를 설정
configProps.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 메시지 값의 역직렬화 클래스를 설정
configProps.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
// 설정된 프로퍼티로 DefaultKafkaConsumerFactory를 생성하여 반환
return new DefaultKafkaConsumerFactory<>(configProps);
}
// Kafka 리스너 컨테이너 팩토리를 생성하는 빈을 정의
// ConcurrentKafkaListenerContainerFactory는 Kafka 메시지를 비동기적으로 수신하는 리스너 컨테이너를 생성
// 이 팩토리는 @KafkaListener 어노테이션이 붙은 메서드들을 실행할 컨테이너를 제공한다.
@Bean
public ConcurrentKafkaListenerContainerFactory<String, String> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
// 컨슈머 팩토리를 리스너 컨테이너 팩토리에 설정
factory.setConsumerFactory(consumerFactory());
// 설정된 리스너 컨테이너 팩토리를 반환
return factory;
}
}
consumer > ConsumerEndpoint
@Slf4j
@Component
public class ConsumerEndpoint {
// Kafka에서 메시지를 소비하는 리스너 메서드
// @KafkaListener: Kafka 리스너로 설정
@KafkaListener(groupId = "group_a", topics = "topic1")
// Kafka 토픽 "topic1"에서 메시지를 수신하면 이 메서드가 호출된다.
// groupId는 컨슈머 그룹을 지정하여 동일한 그룹에 속한 다른 컨슈머와 메시지를 분배받는다.
public void consumeFromGroupA(String message) {
log.info("Group A consumed message from topic1: " + message);
}
// 동일한 토픽을 다른 그룹 ID로 소비하는 또 다른 리스너 메서드
// Kafka 토픽 "topic1"에서 메시지를 수신하면 이 메서드가 호출된다.
@KafkaListener(groupId = "group_b", topics = "topic1")
public void consumeFromGroupB(String message) {
log.info("Group B consumed message from topic1: " + message);
}
// 다른 토픽을 다른 그룹 ID로 소비하는 리스너 메서드
@KafkaListener(groupId = "group_c", topics = "topic2")
public void consumeFromTopicC(String message) {
log.info("Group C consumed message from topic2: " + message);
}
// 다른 토픽을 같은 그룹 ID로 소비하는 리스너 메서드
@KafkaListener(groupId = "group_c", topics = "topic3")
public void consumeFromTopicD(String message) {
log.info("Group C consumed message from topic3: " + message);
}
@KafkaListener(groupId = "group_d", topics = "topic4")
public void consumeFromPartition0(String message) {
log.info("Group D consumed message from topic4: " + message);
}
}
이렇게 Producer와 Consumer 코드를 작성하고 어플리케이션을 실행한다.
kafka-ui와 동작원리 실험
kafka-ui에 접속해서 어떠한 변화가 있는지 본다.
Topics

현재 존재하는 topic은 topic1, topic2, topic3, topic4
Consumers
현재 존재하는 consumer group들 --> group_a, group_b, group_c, group_d
Topic을 test-topic (기존의 topic으로 존재하지 않음) 으로 설정하고 요청을 보내면.
http://localhost:8090/send?topic=test-topic&key=key-1&message=hello
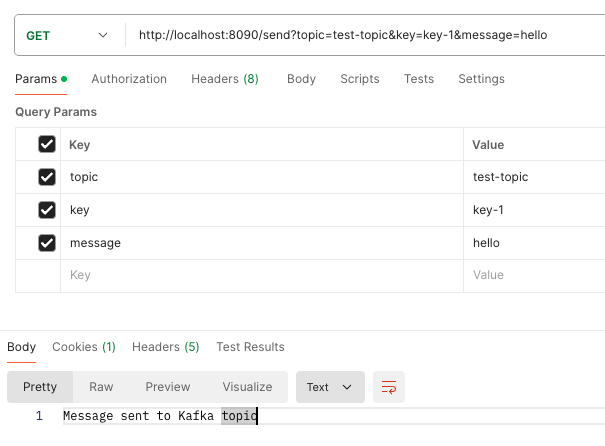
Consumer 는 아무런 반응이 없다. 왜냐하면 해당 topic을 구독하는 컨슈머가 존재하지 않기 때문이다.
kafka-ui에 접속해서 topic을 다시 살펴봤다.
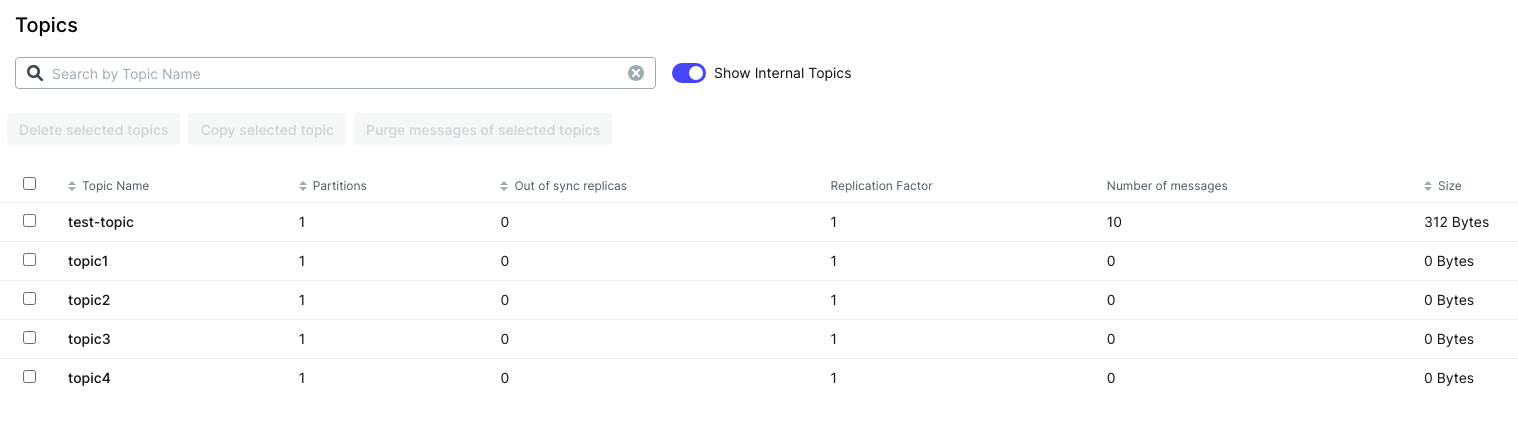
test-topic이 새로 생겼으며, ProducerService에서 메시지를 10개 send하도록 반복문을 돌려논 결과로 메시지의 개수가 10개가 생겼다.
test-topic 내부를 살펴봤다.
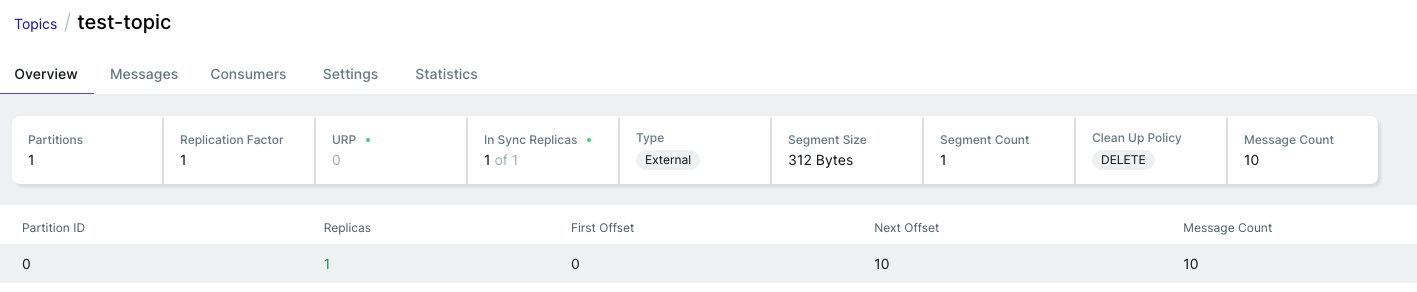
partition 1개가 id=0 값으로 생성되었고,
총 메시지의 개수는 10개,
다음 next offset은 10 (0부터 9가 쓰임) 임을 확인할 수 있다.
Messages 탭
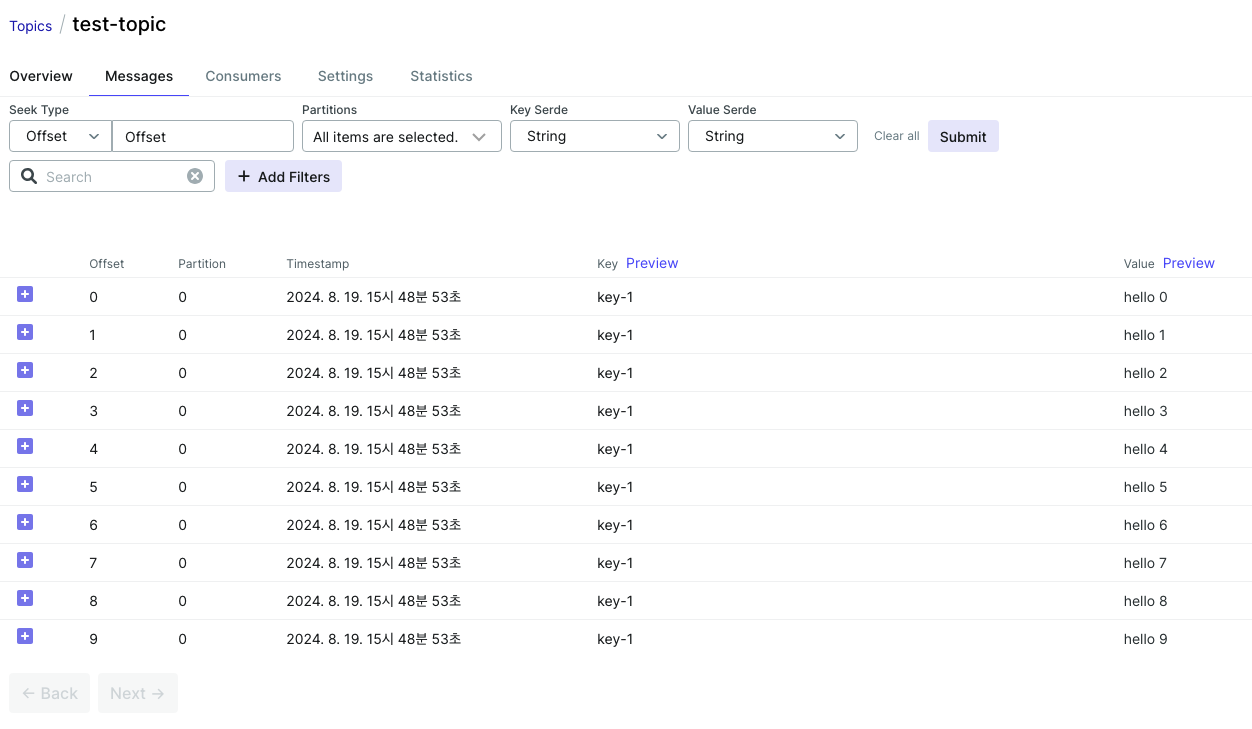
10개의 메시지가 담겨있는 것을 확인할 수 있다. Key 값은 request param으로 설정한 key-1이다.
Consumer 탭
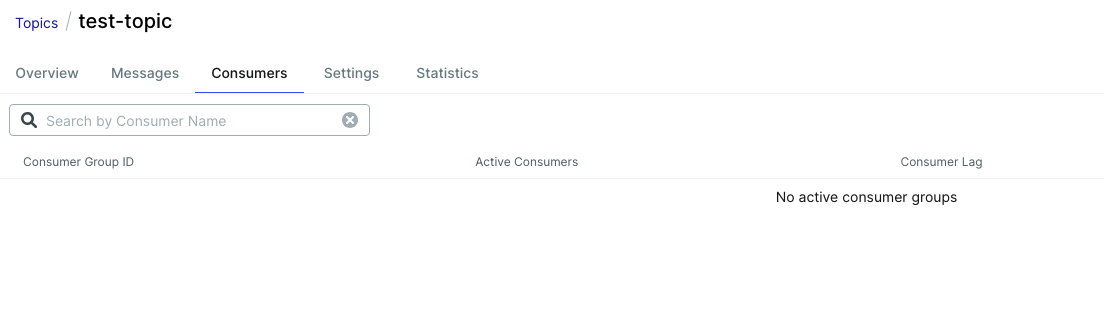
당연히 없었다.
Topic을 topic1으로 설정하고 요청을 보낸다.(기존의 topic1 컨슈머 그룹 2개 - group_a, group_b 존재)
http://localhost:8090/send?topic=topic1&key=key-1&message=hello

같은 토픽으로 서로 다른 2개의 그룹이 같은 메시지를 받고 있다.
마찬가지로 Topic을 topic2, topic3, topic4로 설정하고 요청을 보낸 후 결과를 확인해보자.
그룹이 같더라도 토픽이 다르면, 다른 메시지를 받는 것을 확인할 수 있다.
결국 topic 기준으로 메시지를 받는다는 것을 염두해 두자.
'Backend' 카테고리의 다른 글
| 어플리케이션 성능 테스트 - JMeter (0) | 2024.08.30 |
|---|---|
| RabbitMQ로 SAGA 패턴 구현 (0) | 2024.08.30 |
| Prometheus & Grafana & Loki 모니터링 (0) | 2024.08.20 |
| RabbitMQ 기본 개념 및 실습 (0) | 2024.08.19 |
| 대규모 스트림 처리 (0) | 2024.08.18 |