
CI/CD
각 플러그인마다 .github/workflows 안에 yaml 파일을 작성하여 깃허브에 코드를 push하면,
dockerhub에 업데이트된 이미지가 올라가고, cloudforet에 변경사항이 반영되며,
Slack으로 webhook 알람이 오는 것까지 구축하고 개발을 마무리했다.

Helm chart packaging

Github Collector 플러그인에 대해서 Helm Chart 패키징을 적용해봤다.
Helm Chart Packaging은 Helm 차트를 하나의 패키지로 묶어 .tgz 파일 형식으로 만드는 작업이다.
한 번 패키징된 Helm Chart는 여러 환경에 재사용할 수 있어 동일한 애플리케이션을 다른 클러스터나 환경에 쉽게 배포할 수 있다.
이렇게 하면 Kubernetes 애플리케이션의 배포 파일과 설정을 통합하여 배포를 간편하게 관리할 수 있어서 실무에서 무조건 사용한다고 멘토링할 때 메가존 클라우드 멘토님이 말씀해주셨다.
도커 허브에 이미지를 Push하고, 로컬에서 Pull 받아 사용하는 것과 비슷한 느낌이라고 이해했다.
Helm이 도커 허브, 도커 허브에 올라간 이미지가 Helm Chart와 대응된다고 생각한다.
Helm
Helm은 Kubernetes의 패키지 관리 도구이다.
일반적으로 Kubernetes에서 애플리케이션을 배포하려면 여러 매니페스트 파일을 사용해야 하는데, 이 과정이 복잡하고 파일 간의 관계를 관리하기가 쉽지 않다.
Helm은 이러한 매니페스트 파일들을 하나의 패키지로 묶어 효율적이고 일관되게 애플리케이션을 배포할 수 있도록 도와준다.
Helm은 Kubernetes의 apt 또는 Kubernetes의 yum으로 불릴 정도로 Kubernetes 애플리케이션 관리에 있어 중요하다고 한다.
Helm Chart
Helm Chart는 Helm의 패키지 포맷이다.
쉽게 말해, Helm을 통해 애플리케이션을 배포하기 위해 필요한 모든 매니페스트 파일을 포함하는 템플릿이다. Helm Chart는 Kubernetes 리소스를 정의하는 여러 YAML 파일과 이들을 템플릿화하기 위한 다양한 설정을 포함한다.
- 템플릿 파일: Kubernetes 리소스 정의 파일(YAML 파일)로, 이 파일들을 통해 Kubernetes에 어떤 리소스를 생성할지 정의
- values.yaml: 템플릿 파일이 사용하는 기본 설정 값을 정의하며, 이를 통해 동일한 Helm Chart로도 다른 설정을 적용하여 다양한 환경에서 사용할 수 있다.
- Chart.yaml: Chart에 대한 메타데이터(이름, 버전, 설명 등)를 포함한 파일
예를 들어, WordPress를 Kubernetes에 배포하고 싶다고 하면, Helm Chart에는 WordPress와 관련된 모든 매니페스트 파일(Deployment, Service 등)이 포함되어 있고, 사용자는 Helm을 통해 이 Chart를 배포하면 WordPress 애플리케이션이 Kubernetes 클러스터에 쉽게 설치된다.
그럼 왜 사용하지?
여러 YAML 파일을 관리할 필요 없이, 하나의 Chart를 사용해 손쉽게 여러 리소스를 관리할 수 있고,
동일한 애플리케이션을 여러 환경에 일관되게 배포할 수 있으며,
애플리케이션의 업그레이드와 롤백까지 쉽게 수행할 수 있다.

실제로 yaml 파일이 이렇게 많으면 관리하기 어려울 것 같다.
Github Helm chart packaging
- Github Repository 생성: Helm Chart를 호스팅할 새로운 Github 저장소를 생성한다.
gh-pages브랜치 생성: 이 브랜치를 통해 Github Pages를 설정하여 Helm Chart를 호스팅할 수 있도록 한다.- Helm Chart 생성:
helm create <chart-name>명령어를 사용해 생성한다. - Chart 버전 업데이트:
Chart.yaml파일에서version필드를 업데이트하여 패키징할 때 최신 버전이 적용되도록 한다. - Helm Chart 패키징
명령어를 사용하여 .tgz 파일로 Helm Chart를 패키징한다.
아래 명령어를 실행하면 github-inven-collector-<version>.tgz 파일이 생성된다.
helm package github-inven-collector/
index.yaml 파일 생성
helm repo index 명령어를 사용하여 index.yaml 파일을 생성한다.
이 파일은 Helm Chart 저장소의 메타데이터를 포함한다. --url 옵션에 Github Pages 주소를 설정해준다.
helm repo index . --url https://<github-username>.github.io/<repository-name>
이미 index.yaml 파일이 존재한다면, 새 Chart를 추가할 때 해당 파일을 갱신한다.
helm repo index . --merge index.yaml --url https://<github-username>.github.io/<repository-name>
Github Pages 설정
생성된 .tgz 파일과 index.yaml 파일을 gh-pages 브랜치에 커밋하고 push한다.
git checkout gh-pages
git add <chart-name>.tgz index.yaml
git commit -m "Add new chart version"
git push origin gh-pages- Github 저장소 설정으로 이동하여 Settings > Pages로 이동
- Branch에서
gh-pages를 선택하고 저장하여 Github Pages를 활성화한다.
Helm 저장소 추가 및 사용
로컬에서 해당 저장소를 Helm 저장소로 추가한다.
helm repo add <repo-name> https://<github-username>.github.io/<repository-name>
Helm 저장소 업데이트
helm repo update
Helm Chart 설치
helm install <release-name> <repo-name>/<chart-name>
발생한 이슈와 해결
도커 이미지 버전 관리
Docker hub에 올라간 이미지에 대한 버전을 cloudforet 에서는 해시 값이 아니라 text로 읽어서 구분한다.
docker build, docker push를 버전 태그를 latest로 바꿨을 때 똑같은 버전으로 인식하고 변동사항을 읽어오지 못하는 상황이 발생했다.
그래서 일일이 버전을 명시해서 build, push를 해줘야 하는 번거로움이 있었다.
이를 위해 github actions로 CI/CD를 구축할 때, VERSION 파일의 내용을 읽어 동적으로 version 관리가 되게했다.
따라서 VERSION 파일의 숫자를 변경하고 깃허브에 push만 하면 자동으로 docker build/push, cloudforet 반영까지 이어진다.
name: Docker Image CI
on:
push:
branches: [ master ]
jobs:
build:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v2
- name: Login to Docker Hub
uses: docker/login-action@v2
with:
username: ${{ secrets.DOCKER_USERNAME }}
password: ${{ secrets.DOCKER_PASSWORD }}
- name: Read version from file
id: version
run: |
VERSION=$(cat src/VERSION)
echo "VERSION=$VERSION" >> $GITHUB_ENV
- name: Build and push Docker image
uses: docker/build-push-action@v4
with:
push: true
tags: chanjin/plugin-github-inven-collector:${{ env.VERSION }}
Collector 수집이 안되는 문제
가끔식 Collector가 수집을 못하는 버그가 발생했었다.
kubectl get pods -n cloudforet-plugin
kubectl logs -f <pod_name> -n cloudforet-plugin
위 명령어로 로그를 확인해보았고,
2024-10-30T09:27:42.764Z [INFO] 7a905cce4665861aa6a66c8ba59b3c1d Collector.collect (__init__.py:204) (REQUEST) => {"options": {}, "secret_data": "********", "filter": {}}
2024-10-30T09:37:36.491Z [INFO] 7e9f323737ba3783a60a4f975796c2b6 Job.get_tasks (__init__.py:204) (REQUEST) => {"secret_data": "********", "options": {}}
2024-10-30T09:37:36.492Z [ERROR] 7e9f323737ba3783a60a4f975796c2b6 Job.get_tasks (__init__.py:277) (Error) => ModelMetaclass object argument after ** must be a mapping, not NoneType
error_code = ERROR_UNKNOWN
status_code = INTERNAL
message = ModelMetaclass object argument after ** must be a mapping, not NoneType
Traceback (most recent call last):
File "/usr/local/lib/python3.8/site-packages/spaceone/core/service/__init__.py", line 222, in _pipeline
response_or_iterator = func(self, params)
File "/usr/local/lib/python3.8/site-packages/spaceone/core/service/utils.py", line 62, in wrapped_func
response_or_iterator = func(self, params)
File "/usr/local/lib/python3.8/site-packages/spaceone/inventory/plugin/collector/service/job_service.py", line 34, in get_tasks
return TasksResponse(**response)
TypeError: ModelMetaclass object argument after ** must be a mapping, not NoneType
2024-10-30T09:37:36.572Z [INFO] 19a204960b475d8d48f0ca65e4bf6a66 Collector.collect (__init__.py:204) (REQUEST) => {"options": {}, "secret_data": "********", "filter": {}}
세 컬렉터 모두 똑같은 에러가 발생하는 듯했다.
깃허브 콜렉터 에러를 보니,

엑세스 토큰이 잘못된 것이 문제였고, 만료가 된 것 같아 재발급을 해주었더니 해결됐다.
Github Collector Plugin 성능 개선 및 결과 : 80.19% 수집 시간 단축
깃허브 컬렉터로 데이터를 수집할 때 문제점: 너무 오래 걸린다.

무려 17분 55초가 걸렸었다.

Github Actions의 구조를 보면 위와 같은데, Repository부터 Steps까지 depth가 4라서 모든 데이터를 가져와야 하기 때문에 브루트포스로 짜게 되었고, GithubConnector 에서 각 Repository의 데이터를 가져올 때 내부적으로 4중 for 문을 돌게 되었다.
Github Collector의 버전이 올라갈 때마다 테스트를 진행했는데 그 때마다 18분에 가까운 시간을 소비하는 것은 비효율적이라 판단하여 최적화를 시도했다.
가장 먼저 for문의 depth를 줄이는 것이 최우선이라 생각했는데, Actions의 구조상 불가능하다고 느꼈고, 실제로 for문의 depth를 줄이진 못했다.
대신, 데이터들을 불필요하게 중복으로 가져오는 로직을 확인했고, 그러한 부분들에 대해 최적화를 진행했다.
이 때, 멘토님들의 도움을 받았다. Github에 올린 pull request에 리뷰를 달아서 친절하게 알려주셨다.
https://github.com/ChainsoMen/plugin-github-inven-collector/pull/4
⚡ [Fix] 깃허브 콜렉터 최적화: 수집 시간 단축 - 17m 50s -> 3m 30s by jun6292 · Pull Request #4 · ChainsoMen/pl
기존에 수집하는데 17분 50초 걸렸는데 최적화 후 3분 30초 정도 걸리는 듯합니다. 다음과 같은 변경 사항이 있었습니다. ThreadPoolExecutor를 사용하여 병렬 처리: 스레드 수 10 레포지토리 캐싱: 깃허
github.com
이 문제는 Repository 데이터와 Actions 데이터를 가져오는 부분을 분리하면서 발생했다.
Repository 데이터를 가져올 때 Actions 데이터까지 중복으로 가져오고 있었고, 결국 Actions 데이터는 2번 가져오게 되는 구조였다.
Actions를 가져올 때는 Repository 데이터에 대한 의존성이 있기 때문에 반드시 Repository를 거쳐서 와야 했고, 반대로 Repository만 가져올 땐 Actions 데이터 까지는 가져올 필요가 없는 것이다.
Github Manager에서 Repository와 Actions를 가져오는 함수에서 fetch flag를 두어, Repository의 경우 Actions를 가져오게 하지 않고, Actions만 가져오도록 수정했다.
또한 Github 데이터들을 가져오는 것도 API 호출이므로 멀티 스레딩을 적용했었다.
그 결과, 데이터 수집 시간이 6분대로 감소하였음을 확인했다.
하지만, 파이썬에서는 GIL(Global Interpreter Lock) 때문에 멀티스레딩을 사용하게 된다면 오히려 성능이 떨어질 수도 있다고 하셨고, Cloudforet에서도 inventory 마이크로서비스가 비동기를 지원하지 않으며, 디버깅도 힘들어서 사용하지 않는다고 했다.
그래서 GIL에 대해서 조금 파봤는데, CPU bound와 I/O bound에 대해서 알게 되었고, CPU bound 상황에서는 멀티 스레딩 시 같은 메모리를 참조할 때 스레드 락이 걸려 성능이 오히려 떨어질 수도 있다는 것을 확인했다.
그러나, API 호출은 네트워크 통신이고 이는 I/O bound에 속해서 성능 상 이점을 가져갈 수 있지 않을까라는 게 내 생각이었다.
하지만, 우리 팀은 SpaceONE 오픈 소스 프로젝트를 진행하고 있고, 그 기반인 플러그인 Inventory 마이크로서비스에서 위와 같은 이유로 멀티 스레딩을 사용하지 않기 때문에 멀티 스레딩은 폐기했다.
그 대안으로 캐싱을 적용했다.
@lru_cache 어노테이션을 활용하여 Repository를 가져오는 메서드에 캐싱 처리를 해주었다.
이유는 Repository, Repository + Actions 이므로 중복으로 가져오는 데이터는 Repository이기 때문이다.
이러한 성능 최적화의 결과 깃허브 컬렉터 데이터 수집 시간이 3분대로 줄어드는 쾌거를 이룩했다.
최적화를 통해 약 80.19% 수집 시간을 단축했다.
정리하자면 다음과 같다.
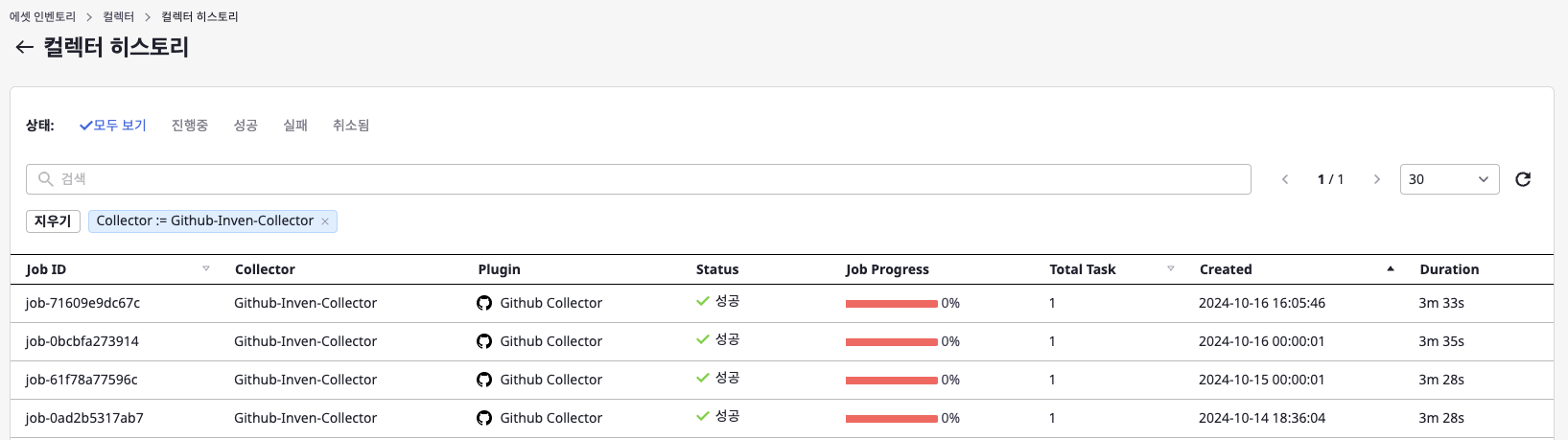
최적화하기 전 수집 시간: 17분 소요

멀티 스레딩 + Actions fetch 로직 적용: 6분 소요
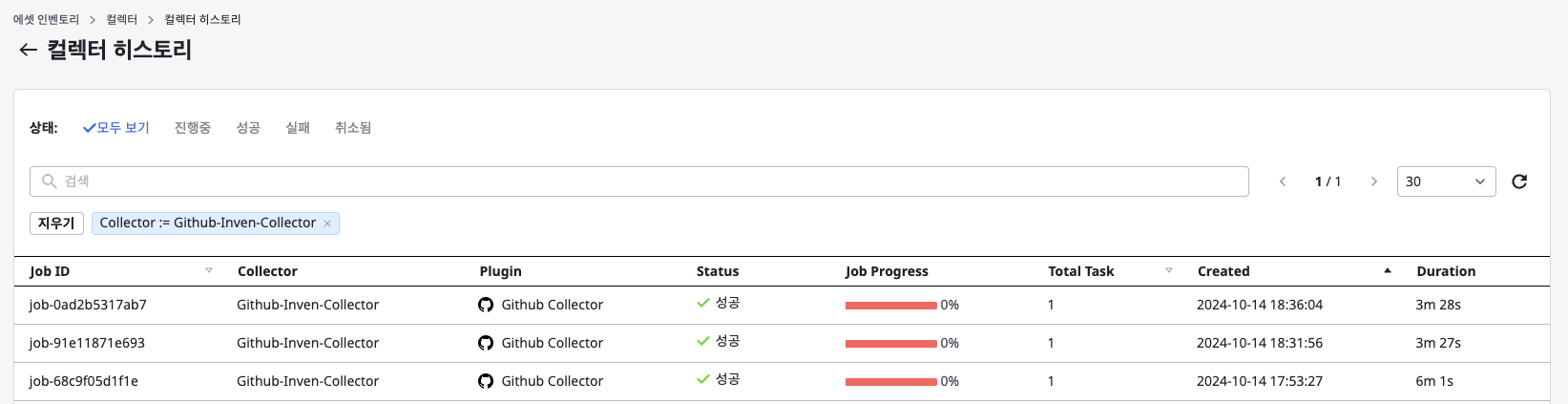
Actions fetch 로직 + 캐싱 적용: 3분 소요
최종 시스템 아키텍처

이렇게 아키텍처를 구성하고 프로젝트는 마무리했다.
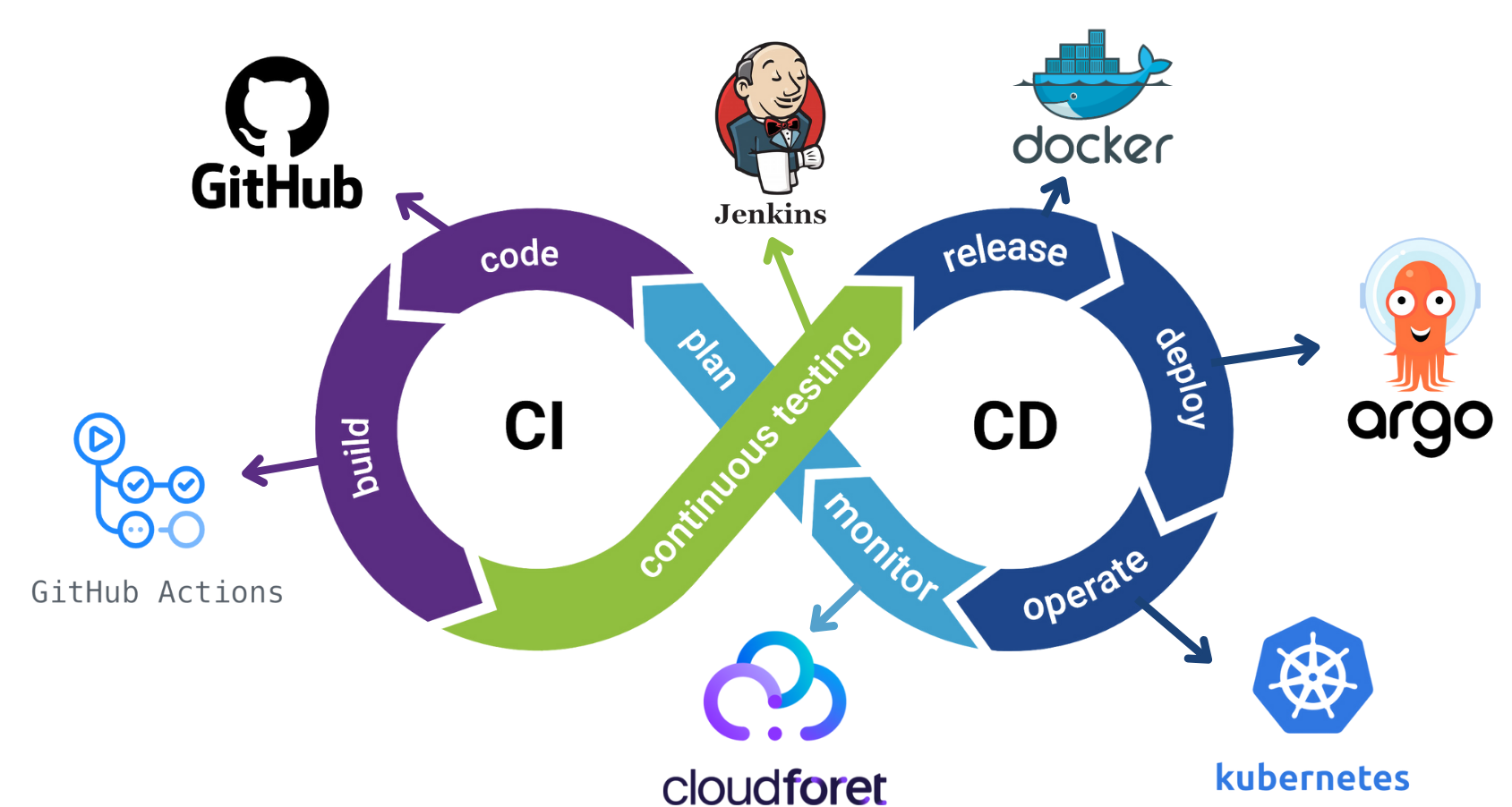
위 그림은 DevOps라는 주제에 맞게 Toolchain의 어느 시점에 어떤 Tool이 쓰이는 지를 시각화한 것이다.
'project > 2024 공개SW 개발자대회' 카테고리의 다른 글
| 2024 공개SW 개발자대회 복기2 - 플러그인 개발기 (0) | 2024.11.14 |
|---|---|
| 2024 공개SW 개발자대회 복기1 - 개발 환경 구축기 (0) | 2024.11.13 |
| 2024 공개SW 개발자대회 1차 합격 복기 (0) | 2024.09.10 |